Regex for Japanese text letter counting
01 Apr 2015Japanese text can be thought of a mixture of Chinese characters known as Kanji, and the two phonetic alphabets of Hiragana and Katakana. Japanese text has no white spaces between words and one Kanji character can stand in for a whole word. This makes it difficult calculate how to fairly change clients for Japanese to English translation work. In Japan, the loosely agreed procedure is to charge by the letter, but when charging for every single letter, there are some characters that must be removed before calculating the total per letter fee. Some examples are English letters, numbers, white spaces, carriage returns, periods and other symbols in both Japanese and English. Removing these characters changes the text below from 135 characters
Revision History: 1.2.6. 2015-1-29 iOS8.1.2(8.1,8.1.1)に対応。 CPU使用効率のさらなる最適化 さらなる高音質を追求 波形アナライザーの表示のさらなる最適化 "シャッフル機能の選曲リスト連動"機能を追加 (「設定」→「一般」) 各種微調整
to 72 characters.
に対応使用効率のさらなる最適化さらなる高音質を追求波形アナライザの表示のさらなる最適化シャッフル機能の選曲リスト連動機能を追加設定一般各種微調整
A significant difference when the translation work is priced by letters.
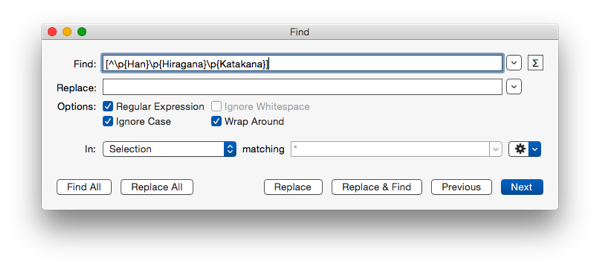
So how exactly do you remove all the cruft for the calculation? You could combing through the text yourself and manually delete letters one by one but Ain’t Nobody Got Time for That! So regex to the rescue. If the text is in Unicode the following regex will match any characters, including symbols, that are not Kanji, Katakana, or Hiragana.
[^\p{Han}\p{Hiragana}\p{Katakana}]
Use it in a text editor that has a regex friendly find and replace, like TextMate and done.